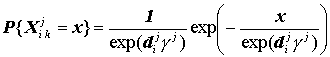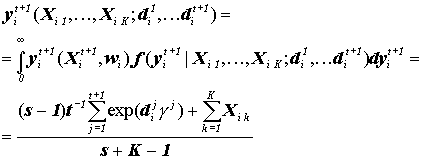Библиотеку
|
| Вернуться в Библиотеку | Содержание | << 7 >> |
|
Библиотека
|
3.2. Компонент величины убытка. Предположим, что застрахованный i находится в системе в течение t лет. Будем считать, что число спровоцированных им ДТП в течение года j составляет Ki j ; общее число спровоцированных им ДТП есть K; а Xijk обозначает величину убытка от страхового случая k в году j. Тогда вся информация, которую мы имеем о вызванных данным застрахованным убытках можно представить в виде вектора Xi 1, Xi 2, …, Xi K; а общий объем убытков для данного застрахованного за t периодов, в течение которых мы его наблюдаем будет равен Xi 1+ Xi 2+ …+ Xi K. Мы предполагаем, что Xijk имеет экспоненциальное распределение со средним yi j, которое есть ожидаемая величина убытка в период j для застрахованного i. Как мы уже говорили, застрахованные имеют неодинаковые прогнозируемые величины убытка, их стоимость для страховщика не одинаковы, следовательно будет честно, если каждый застрахованный будет платить премию пропорциональную ожидаемой величине убытка. Предположим, что ожидаемая величина убытка есть функция h индивидуальных характеристик риска di j = ( di j1 , …, di jh ), т.е. априорных рейтингующих переменных. Мы сделаем специальное предположение, что yi j = exp( di j g j ), где g – вектор коэффициентов. Неотрицательность yi j вытекает из экспоненциальной зависимости. Тогда плотность распределения Xijk есть:
В этой модели мы приняли, что h индивидуальных характеристик риска дают достаточно информации для определения ожидаемой величины убытка. Однако, если это не так, тогда в регрессию надо ввести случайный компонент zi . Тогда мы можем записать: yi j = exp( di j g j + zi) = exp( di j g j ) wi Где wi = exp(zi) рандомизирует yi j. Если мы предположим, что wi имеет Инвертированное Гамма распределение с параметрами s и s–1, причем s > 2. При этом среднее wi равно 1, а его дисперсия – (s–2)–1. Тогда yi j имеет Инвертированное Гамма распределение с параметрами s и (s–1) exp( di j g j ), а плотность распределения Xijk будет иметь вид:
Что соответствует распределению Парето с параметрами s и (s–1) exp( di j g j ). Можно показать, что данная параметризация не воздействует на результат, если в регрессию подставить константу. Среднее мы установили равным 1, чтобы ожидание zi было равно нулю. Мы также имеем: E Xijk = exp( di j g j ), D Xijk = (s–1) exp2( di j g j )[ 2(s–2)–1 – (s–1)–1 ] Страховщику нужно определить наилучшую оценивающую функцию для ожидаемой величины убытка в течение периода t+1, используя данные об убытках за t
периодов, а также известные индивидуальные характеристики риска за t+1 период. Давайте обозначим эту оценивающую функцию Используя классическую квадратичную функцию потерь, можно продемонстрировать, что оптимальной оценивающей функцией для средней величины убытка в периоде t+1, при заданных Xi 1, …, Xi K и di 1, …, di t+1 будет среднее апостериорного Инвертированного Гамма распределения которое равно:
Если t=0, то рейтингование застрахованных проводится только на основании априорных данных, что означает, что yi 1 = exp( di 1 g j ). |