|
Библиотека Инструменты Все Страховщики Рейтинги Доп.Инфо Законодательство Ссылки. Советы Магазин Написать
|
2.3. Расчет премий в соответствии с Принципом Чистых Премий.
Как показано выше, ожидаемое число убытков в следующем году lt+1(k1 ,…, kt) для застрахованного
или группы застрахованных, кто в течении t лет наблюдения спровоцировал K убытков с общим объемом x1 + x2 + …+ xK,
определяется формулой (1); а прогнозируемая средняя величина отдельных убытков yt+1(x1 , x2 ,…, xK) определяется (2).
Тогда чистые премии, которые должны быть уплачены за страховку для данной группы застрахованных должны быть равны произведению lt+1(k1 ,…, kt) и yt+1(x1 , x2 ,…, xK), т.е. они
будут равны:
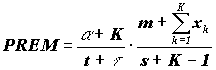 (3) (3)
Для того, чтобы рассчитать премии, которые должны быть уплачены, мы, таким образом, должны знать:
- Параметры Отрицательного Биномиального распределения a и t (о том, как можно оценить параметры этого
распределения можно посмотреть в Lemaire (1995)).
- Параметры распределения Парето s и m ( то, как оценивают параметры распределения Парето можно посмотреть, например, в Hogg and Klugman (1984))
- Число лет t в течение которых данный застрахованный находится в нашем портфеле.
- Число убытков K, которые произошли с этим застрахованным.
- Общий объем его убытков x1 + x2 + …+ xK.
Все эти величины могут быть достаточно просто определены; а принимая во внимание то, что Отрицательное Биномиальное распределение часто используется при аппроксимации
распределения числа убытков, а распределение Парето – для объема убытка, это все увеличивает возможности применения модели.
2.4. Основные свойства оптимальной BMS, в которой учитывается частота и величина убытков.
- Система является честной по отношению ко всем застрахованным, поскольку за каждого из них платится премия пропорциональная частоте и величине его убытков, принимая
во внимание, путем использования Теоремы Байеса, всю информацию о количестве убытков и величине убытков за все время, пока застрахованный находится в нашей системе. Мы
используем точное значение величины каждого произошедшего убытка, чтобы произвести дифференциацию среди застрахованных имеющих равное количество убытков, а не только
чтобы построить шкалу величины убытков по всему портфелю.
- Система является финансово сбалансированной. Ожидаемая величина суммарных по портфелю страховых премий, собранных в течение каждого отдельного года, остается
постоянной и равной:
P = a t –1 m (s –1) –1 (4)
Чтобы доказать равенство (4), достаточно показать, поскольку мы считаем частоту и величину убытка независимыми величинами, что:
EL L = E [ E [ l | k1, …, kt ] ] =
a / t и
EY Y = E [ E [ y | x1, …, xk ] ] = m / (s –1)
Доказательство первого равенства можно найти в Lemaire (1995), а второго – в Vrontos (1998).
- В начале все страхователи платят равную премию, которая определяется (4).
- Чем большее число ДТП было спровоцировано застрахованным, и чем больше был ущерб, тем выше будут его премии в будущем.
- Премии всегда снижаются, если не произошло ни одного страхового случая.
- У застрахованных, которые стали виновниками ДТП с малым объемом убытка, появляется дополнительный повод сообщить о нем, если им будет известно, что величина убытка
будет учтена страховщиком и премия для него будет меньше, чем для того, кто стал виновником крупного ДТП. При таком дизайне системы бонусов и штрафов феномен “бонусного
голода” будет иметь меньший масштаб, а оценка частоты и величины убытка будет более аккуратной. ( О проблемах бонусного голода и оценке параметров распределения
убытков смотрите здесь. )
- Введенный нами в BMS компонент, отвечающий за величину убытка, может оказаться более важным с практической точки зрения, чем количество убытков, поскольку именно
этот компонент определяет затраты страховщика при урегулировании убытка, а значит должен определять и премии.
- Функция, использованная для оценки среднего убытка, не является простой, и поэтому чувствительна к дисперсии. На практике могут быть использованы более простые
функции. ( т.е. усечение рядов данных, М-оценивание )
|
