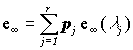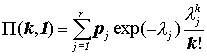Библиотеку
|
| Вернуться в Библиотеку | Содержание | << 3 >> |
|
Библиотека
|
Как и в случае любой другой BMS, мы здесь имеем несократимую (не имеющую циклов) Марковскую цепь, где все состояния эргодичны ( достижимы из других состояний). В этих условиях существует стационарное распределение вероятностей, которое определяется как: e¥(l) = limn ® ¥ Qn e0(l) Здесь e0(l) обозначает некоторое начальное распределение водителей в BMS. Стационарное распределение вероятностей не зависит от начального.Стационарное распределение вероятностей можно также получить, решая e¥(l) = e¥(l)Q При выполнении нормализующего условия: Сумма всех компонентов вектора e¥(l) должна быть равна 1.Если нас интересует стационарное распределение всего портфеля (e¥), то мы должны просто взять взвешенное среднее стационарных распределений для различных типов страхователей (различных l; см. детали в Walhin & Paris (1999) ). При нашей непараметрической аппроксимации портфеля смешанным Пуассоновским распределением имеем:
Таблица 6. Стационарное распределение водителей.
Заметьте, что если стационарное распределение еще не достигнуто, то можно без проблем работать с промежуточным распределением. Распределение участников внутри BMS через Т лет задается формулой: eT (l) = QT e0 (l) 5. Формулировка задачи. Когда собираются данные на рынке, если BMS уже действует, мы не наблюдаем правильные распределения величины убытка и частоты страховых случаев. Ибо на наблюдаемые данные влияет стремление страхователя получить бонус.Реальное распределение величины убытка должно иметь более низкое среднее, а реальное распределение частоты убытков должно иметь более высокое среднее. Давайте предположим, что часть всех водителей, p , всегда сообщает об убытках, а остальные водители (их доля равна 1 – p) сообщают только об убытках, величина которых превосходит оптимальное удержание задаваемое алгоритмом Lemaire.Давайте также предположим, что была выполнена непараметрическая аппроксимация распределения частоты убытка для наблюдавшихся выплат. В ее ходе обнаружились r классов риска lj , имеющих вероятность pj . Данное распределение (N) не есть распределение числа страховых случаев, а лишь распределение числа страховых случаев, о которых было сообщено страховщику. Функцию плотности (df) распределения N можно записать:
Пусть X – случайная величина, представляющая заявленный объем убытка. Пусть Z – случайная величина; реальный объем убытка. Эта переменная не известна, поскольку наблюдать можно только Х. Плотность распределения X есть функция от плотности Z и можно записать: fX(x) = fZ(x)+(1–p) fZ(x) П{x³ c} / (1 – FZ(c) ) Здесь с – средняя величина удержания для портфеля.Наша цель определить распределения для Z и для N’. |