
Библиотеку
|
| Вернуться в Библиотеку |
|
Библиотека
|
Рекуррентные формулы для расчета составных распределений. Рекурсия Panjer’a. В 1981 году Panjer предложил метод для расчета составного распределения одномерного распределения, когда составное распределение есть сумма случайного числа независимых и одинаково распределенных случайных величин, причем количество слагаемых также независимо от всех слагаемых. Во всех рекурсивных методах предполагается, что слагаемые есть целочисленные положительные случайные величины ( Или можно считать, что они являются таковыми с точностью до положительного множителя; на результат это не влияет. ) Пусть р – распределение числа слагаемых, например, числа страховых случаев; f – распределение величины слагаемых, например, величины убытка при страховом случае; а g – составное распределение, например суммарного убытка за период времени от страхового портфеля. Тогда:
Где f n* обозначает n-кратную свертку f . Если мы ограничимся лишь целыми положительными значениями Х, то мы получим f n*(x) = 0 , для всех n > x . Тогда :
В частности g(0) = p(0). Если р удовлетворяет рекуррентному соотношению p(n) = ( a + bn–1 ) p(n–1) (В частности этому соотношению удовлетворяют геометрическое распределение и Пуассоновское распределение числа событий. ), то для составного распределения верна формула:
Эта формула и была получена в Panjer (1981).
Применимость Рекуррентных формул. Но непрерывное распределение в рекуррентную формулу не подставить, поэтому приходится проводить дискретизацию. А в ходе дискретизации необходимо: а) Минимизировать потери информации, и связанные с этим отклонения расчетной функции составного распределения; б) Построить распределение с минимальным числом точек, чтобы ускорить расчеты. |
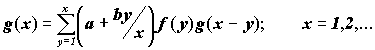 (1)
(1)